With more and more companies using machine learning to guide their choices, it’s now essential to understand how these models form their predictions. Merely developing and enlarging model production isn’t adequate to create better outcomes.
One major challenge with AI models is explainability- understanding how and why the model arrived at a certain decision. This isn’t easy because AI models often use complex algorithms that are not transparent to the user. Explainability is important for several reasons. First, it can help to build user trust in the model. Second, it can help to identify potential errors in the model. Finally, it can help users understand the model’s decision-making process to provide feedback and improve the model over time. There are several methods for improving explainability, such as visualizations and local interpretable models. However, there is still much work to be done in this area.
Explainable AI is important because it helps create transparency and trust in AI systems. By understanding why an AI system has made a particular decision, we can ensure that it is fair and unbiased. Additionally, by building trust in these systems among consumers and businesses, we can encourage the development and use of AI technologies.
Why is Model Explainability required?
- Being able to interpret a model not only increases trust in the machine learning model, but it also becomes all the more important in scenarios involving life-and-death situations. These include fields such as healthcare, law, and credit lending. Let’s say, for example, that a model predicts cancer — the healthcare providers should be aware of which variables are available to them and which variables are more important than others for the model to come to this decision. E.g., Are there any high correlations between variables like age, fitness, etc?
- After comprehending a model, we can discern whether any bias is included. For example — If a healthcare model has only been exposed to American citizens, it likely will not be ideal for those of Asian descent.
- While developing a model, it becomes increasingly important to be able to debug and explain the model.
- It’s essential to be able to explain your models’ results to regulatory organizations such as the Food and Drug Administration (FDA) or National Regulatory Authority for them to approve its use. It also helps ensure that the model is fit for deployment in a real-world setting.
How does explainable AI work?
Explainable AI uses various techniques to explain the decision-making process of AI models. These techniques include explanation graphs, decision trees, and local explanations.
Explanation graphs show how data is processed by an AI model. This can help us understand why a particular decision was made. For example, if an AI model is used to recommend products, the explanation graph could show how the individual’s purchase history was used to make the recommendation.
Decision trees are a type of flowchart that shows how a particular decision was made. This can help us understand why a particular decision was made and how it was influenced by other factors. For example, if an AI model is used to predict whether or not a customer will churn, the decision tree could show how different factors (such as payment history or product usage) were used to make the prediction.
Local explanations are explanations for specific decisions made by an AI model. They provide more detail than explanation graphs or decision trees and can help us understand why a particular decision was made. For example, if an AI model is used to recommend products, the local explanation for a particular recommendation could show which products were considered and why they were chosen.
Explainability Approaches
There are three different approaches to model explainability:
- Global
- Local
- Cohort
Global Explainability Approach:
The Global Approach explains the model’s behavior as a whole. With global explainability, you can understand which features in the model contribute to the model’s predictions. For example, when recommender models are being used, product teams might want to know which features influence customer decisions positively and explore why this is so.
Local Explainability Approach:
Local interpretation helps us understand how the model behaves in different areas, or neighborhoods. This gives us an explanation of each feature in the data and how it contributes to the model’s prediction.
Local Explainability can be very helpful in finding production issues and their root cause. Additionally, it allows you to understand which features have the most impact on model decisions. This is crucial, especially for finance and health industries where one feature could be almost as important as all combined. For example, if your credit risk model rejected an applicant for a loan.
Local explainability allows you to see why a decision was made and how you can advise the applicant better. It also helps when trying to comprehend if the model is fit for deployment.
Cohort Explainability Approach:
Cohort (or Segment) explainability lies between global and local explainability. This type of explainability involves how segments or slices of data play into the model’s prediction. When validating a model, Cohort Explainability can help to show why the model is predicting one way for a group that it performs well with versus another way for a group where it doesn’t perform as impressively. Additionally, this comes in handy when needing to justify outliers- which tend to happen within localized neighborhoods or data sets.
It’s important to note that both Local and Cohort (Segment) explainability can be used to identify outliers. There are a variety of different methods you can utilize for this, such as Shap, Partial Dependence Plot, LIME, or ELI5. One question you may have when dealing with explainability is: which parts of the model are being explained and why does that part matter? Let’s take a closer look at this question…
What aspects of the model are being described, and why is that part essential?
- Features: The features of the model are what make up the main components of the model and they are typically the primary source of explanation for how the model works.
- Data characteristics: These can include: data format, data integrity, etc. Production data are constantly changing, so it is important to log and monitor those changes to better understand and explain the model’s output. Data distribution shifts can impact model predictions, so maintaining the data distribution and having a good understanding of the data characteristics is important for model explainability.
- Algorithms: The choice of algorithms and techniques used when training a model is as important as the data itself. These algorithms define how the features interact and combine to achieve the model output. A clear understanding of the training algorithms and techniques is essential for achieving model explainability.
In order to achieve explainability, you need tools that can explain your model both globally and locally.
The benefits of explainable AI
One of the main benefits of explainable AI is that it helps ensure that AI models are fair and unbiased. By understanding why an AI model has made a particular decision, we can check to make sure that it wasn’t biased in any way. For example, if an AI model is used to recommend products, we can check to make sure that it didn’t recommend products from a certain company or category more often than others.
Another benefit of explainable AI is that it builds trust in AI systems among consumers and businesses. By explaining how decisions are made, explainable AI can help dispel fears about how AI works and show that these systems are trustworthy. This can encourage the development and use of AI technologies.
How to Achieve Explainability with Katonic
Explainable AI is becoming increasingly important as organizations move towards deploying ML models into production. By understanding the different components of explainability, such as features, data characteristics, algorithms, and tools, organizations can better ensure that their AI models are fair and unbiased and build trust with customers.
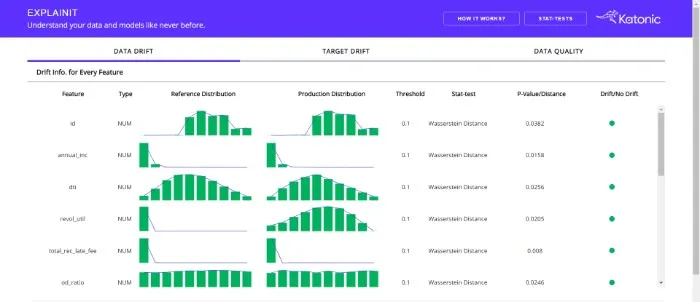
Katonic’s MLOps platform provides data scientists and ML engineers with explainability, monitoring, automation, investigative tools, and visibility to understand why models predict what they do. Explainit is the open-source component of Katonic’s MLOps platform that allows teams to analyze drift in the existing data stack, prepare a summary of productionized data and analyze the in-depth relationships between features and targets. With Explainit, ML platform teams can monitor productionized batch data and build towards an explainability/monitoring platform that improves collaboration between engineers and data scientists.
You can get hands-on with Explainit here.