The modern machine learning workflow requires two essential components – a feature store and an MLOps platform. A feature store serves as a central repository for data, allowing data engineers, data scientists, and other stakeholders to easily manage, store, and share features across projects. An MLOps platform enables teams to automate many of the tasks involved in the machine learning workflow, from model development to deployment and serving. Together, these components help organizations accelerate their machine learning workflows and unlock new insights that drive better business outcomes.
Why should I use a feature store?
Data in feature store is used for feature exploration and engineering, model iteration, training, and debugging, feature discovery and sharing, production serving to a model for inference, operational health monitoring.

Introducing Hopsworks: The Data-Intensive AI Platform for the Enterprise
Hopsworks is an open source, self-managed commercial, and fully-managed cloud service feature store that is built on Apache Hudi/Hive, MySQL Cluster and HopsFS. It supports AWS and Azure (managed service), GCP and on-prem (self-managed).
Hopsworks is a powerful tool that bring the following benefits to table –
- Feature Versioning: Supports version control for features, allowing teams to track changes to features over time. This helps ensure that features are consistent across the machine learning pipeline.
- Collaboration: Supports collaboration across teams. It provides a central location for teams to store, manage, and share features.
- Metadata Management: Provides rich metadata management capabilities, enabling teams to track information about features such as data sources, feature definitions, and transformations.
- Feature Serving: Supports feature serving, enabling teams to easily serve features to machine learning models in production.
- Data Validation: Includes data validation capabilities, allowing teams to validate the quality of features and ensure they meet defined criteria.
- Lineage Tracking: Enables teams to track the lineage of features, providing visibility into the data sources, transformations, and other operations that were used to create each feature.
- Integration: Integrates with a wide range of other tools and frameworks, including Apache Spark, TensorFlow, and PyTorch.
Why should I integrate feature store with MLOps platform?
Integrating a feature store with an MLOps platform has numerous benefits. It provides consistent feature management, improves model quality, accelerates model development and deployment, encourages collaboration and communication across teams, and simplifies governance and compliance.
- Consistent Feature Management: A feature store provides a centralized repository for features, which can be shared across different teams and projects. Integrating the feature store with an MLOps platform ensures that the same set of features is used consistently across the machine learning workflow, from model development to deployment and serving.
- Improved Model Quality: By using a feature store to manage features, it becomes easier to track and manage feature changes and ensure data consistency. This can lead to better model quality and accuracy. Additionally, by integrating the feature store with an MLOps platform, models can be tested and validated before deployment, ensuring that they perform as expected in production.
- Faster Model Development and Deployment: An MLOps platform can automate many of the tasks involved in the machine learning workflow, such as data preprocessing, model training, and deployment. By integrating the feature store with an MLOps platform, data scientists can easily access the features they need, and models can be developed and deployed more quickly.
- Better Collaboration and Communication: By using a feature store and an MLOps platform, teams can collaborate more effectively and communicate more easily. Data scientists, data engineers, and DevOps teams can all work together in a unified platform, which can lead to better results and faster time-to-market.
- Simplified Governance and Compliance: By integrating a feature store with an MLOps platform, it becomes easier to manage data governance and compliance. Features can be tracked and audited, and compliance requirements can be enforced across the machine learning workflow. This can help organizations ensure that they are meeting regulatory requirements and maintaining data privacy and security.
Katonic.ai: Empowering your business with AI solutions
Katonic.ai provides a powerful and versatile machine-learning platform that is scalable and flexible. collaborative platform with a unified UI to manage all data science in one place. The Platform combines the creative scientific process of data scientists with the professional software engineering process to build and deploy Machine Learning Models into production safely, quickly, and in a sustainable way. It offers a variety of advantages over more traditional cloud-based machine learning solutions.
- Runs on any Platform: Compatible with all popular cloud platforms, as well as on-premises and hybrid multi-cloud environments.
- Autoscaling of resources: Supports autoscaling for efficient use of computing infrastructure, making it an ideal choice for businesses that need to quickly scale up or down.
- Open Access to Data: Katonic also provides data connectors to a wide variety of databases, cloud storage solutions, NoSQL databases, and more, allowing users to access their data from many different sources without having to move it. Also, with Katonic, you can easily access your stored data regardless of where it lives.
- Choice of Cutting-Edge Development Tools: The development environments in Katonic allow data scientists to customize their packages and tools, unlocking innovation with sandboxes that can be secured, audited, and shared. It also supports various data science development tools like Jupyter, RStudio, VS Code.
- On-demand distributed compute clusters: Quickly spin up and down compute clusters in Spark, Ray, and Dask allowing data scientists to accelerate computationally demanding tasks greatly. The cluster could see a speed increase of anywhere from 10 to 100 times.
- Build Interactive apps: Interactive apps created with Shiny, Dash Streamlit, and Flask allow non-technical users to interact with models in a user-friendly way. These web apps leverage the power of machine learning and predictive analytics without needing any technical background.
- Integrated Model Monitoring: Automatically collects instrumented prediction and ground truth data so you can monitor deployed models for data drift and accuracy. You can set notifications when quality checks exceed thresholds. When a model drifts, you can easily drill down into model features to quickly modify, retrain and redeploy models.
- Integrated Governance & Reproducibility: Katonic automatically tracks and versions all assets, including data, code, pipeline, computing, experiments, models, batch jobs, and apps. You can instantly roll back to or recreate the exact environment used to create a model to streamline auditing, governance, compliance, and regulatory reporting. Sync code and project status with Git and Jira to integrate data science into broader enterprise project processes. With Katonic, your scientists collaborate with one another for improved model quality and productivity.
Business impact or outcome that Katonic MLOps platform provides are:
- 12x faster deployment of models in the production environment.
- Around 85% reduction in manual labor costs through automation and higher productivity of the data science team.
- 7x reduction in computing cost through Kubernetes microservices architecture and effective management of data science work loads.
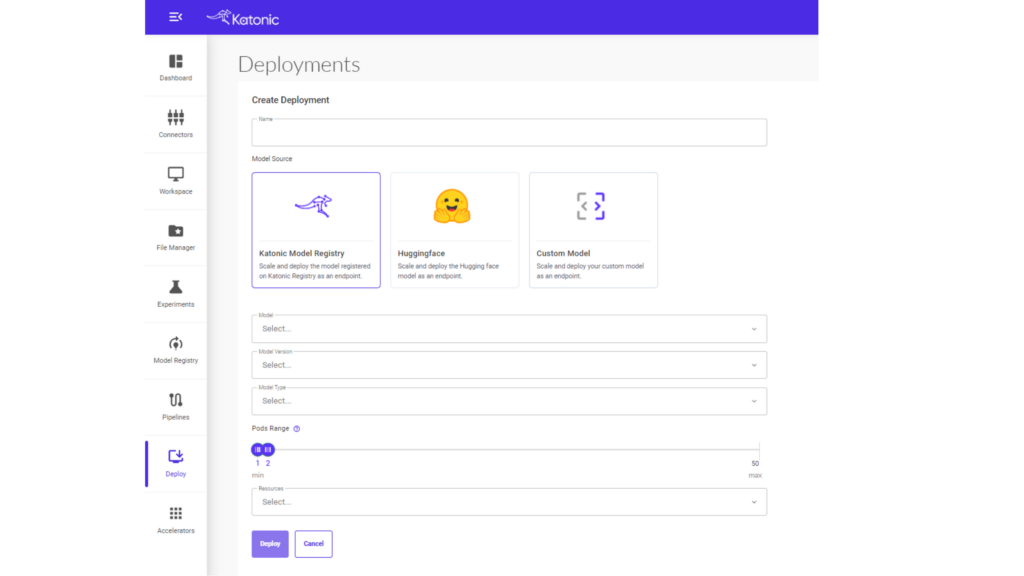
An end-to-end ML pipeline with a feature store and MLOps platform is a complete solution that covers the entire lifecycle of machine learning, starting from data preparation and feature engineering to deployment and monitoring of ML models.
End to end ML pipeline with Hopsworks and Katonic
At the core of this pipeline is a feature store like Hopsworks – a centralized repository that stores curated and engineered features for ML models. It allows data scientists and ML engineers to easily access, share, and reuse features without having to rebuild them from scratch each time. This significantly speeds up the model development process and ensures consistency in feature definitions across the entire ML workflow.
The MLOps platform like Katonic.ai, on the other hand, is a set of tools and services that are designed to streamline and automate the operational aspects of the ML pipeline. It includes features such as automated model deployment and testing, version control, monitoring, and feedback loops for continuous model improvement. By using an MLOps platform, organizations can reduce the time and resources required to deploy and manage ML models and minimize errors that may arise from manual processes.
The combination of a feature store and MLOps platform allows for efficient feature engineering and management, as well as streamlined deployment and management of ML models. With these tools, organizations can build high-quality ML models faster and at scale, accelerating their journey to becoming an AI-driven enterprise.
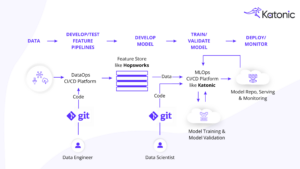
How to integrate Hopsworks with Katonic –
Model training and testing with the Katonic platform and Hopsworks feature store involves a eight-step process
1. Login to the Katonic platform and create a Python workspace
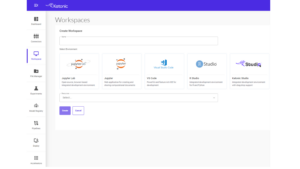
2. Establish the data science project structure, which includes organizing data, setting up code files, and defining workflows.
3. Begin data wrangling and preparation steps to ensure that the data is clean, complete, and ready for analysis.
# loading pre-processed data
import pandas as pd
data = pd.read_csv("https://raw.githubusercontent.com/Katonic-ML-Marketplace/Bank-Loan-Default-Prediction/main/data/bank_loan_preprocessed.csv")
4. Utilize the Hopsworks Open-Source SDK to login to Hopsworks from a notebook using an API token generated and collected on the Hopsworks Platform.
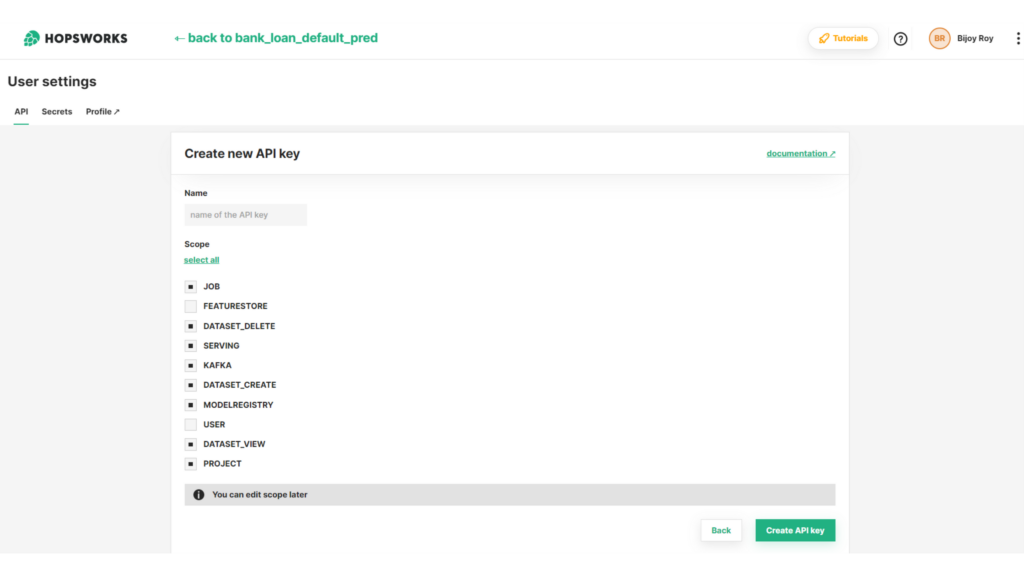
# installing hopsworks sdk
!pip install hopsworks==3.0.5
import hopsworks
project = hopsworks.login(api_key_value=API_TOKEN)
fs = project.get_feature_store()
5. Create a feature group within Hopsworks and ingest data into the feature store.
bank_fg = fs.get_or_create_feature_group(
name="bank_default_batch_fg",
version=1,
description="Credit applicants data",
primary_key=["id"],
event_time="event_timestamp"
)
bank_fg.insert(data, write_options={"wait_for_job": False}) # Writing the Data to the Feature Store.
6. Use the Hopsworks SDK to obtain specific feature data for training and testing machine learning models.
cols = [
'annual_inc', 'short_emp', 'emp_length_num',
'dti', 'last_delinq_none', 'revol_util', 'total_rec_late_fee',
'od_ratio', 'bad_loan', 'grade_A', 'grade_B', 'grade_C', 'grade_D',
'grade_E', 'grade_F', 'grade_G', 'home_ownership_MORTGAGE',
'home_ownership_OWN', 'home_ownership_RENT', 'purpose_car',
'purpose_credit_card', 'purpose_debt_consolidation',
'purpose_home_improvement', 'purpose_house', 'purpose_major_purchase',
'purpose_medical', 'purpose_moving', 'purpose_other',
'purpose_small_business', 'purpose_vacation', 'purpose_wedding',
'term_36_months', 'term_60_months'
]
ds_query = bank_fg.select(cols)
feature_view = fs.create_feature_view(
name='loan_default_fraud_batch_fv2',
version=1,
query=ds_query,
labels=["bad_loan"],
)
td_version, td_job = feature_view.create_train_validation_test_split(
description = 'load default fraud batch training dataset',
data_format = 'csv',
validation_size = 0.2,
test_size = 0.1,
write_options = {'wait_for_job': True},
coalesce = True,
)
feature_view = fs.get_feature_view("loan_default_fraud_batch_fv2", 1)
X_train, X_val, X_test, y_train, y_val, y_test = feature_view.get_train_validation_test_split(1)
7. Train and experiment with the model within the Katonic platform and register the best model using the Katonic SDK.
# installing katonic sdk
!pip install katonic[ml]==1.6.0
from katonic.ml.client import set_exp
from katonic.ml.classification import Classifier
# Creating a new experiment using set_exp function from ml client.
set_exp("default-loan-prediction-feature-store")
# Let's Initialize an object for Our Auto ML Classifier along with the training, testing data and an experiment name.
classifier = Classifier(
X_train,
X_test,
y_train,
y_test,
experiment_name="default-loan-prediction-feature-store"
)
classifier.LogisticRegression()
runs = classifier.search_runs(classifier.id)
runs
best_model = runs.run_name[0]
best_run_id = runs.run_id[0]
classifier.register_model(
model_name=best_model,
run_id=best_run_id
)
8. Deploy the model in production, allowing it to be consumed within the application. This involves setting up the infrastructure necessary for hosting and serving the model, as well as ensuring it is integrated correctly into the application.