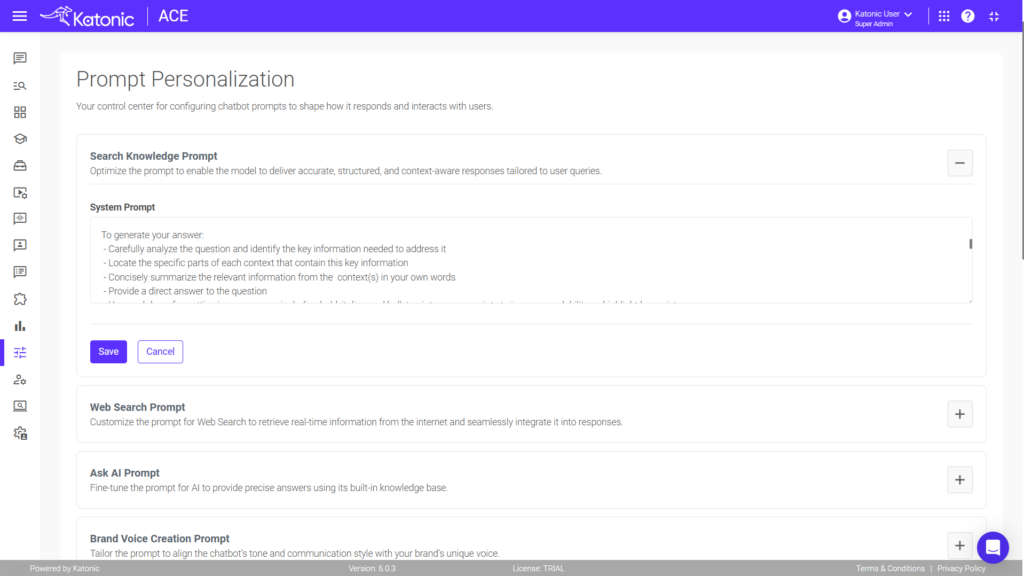
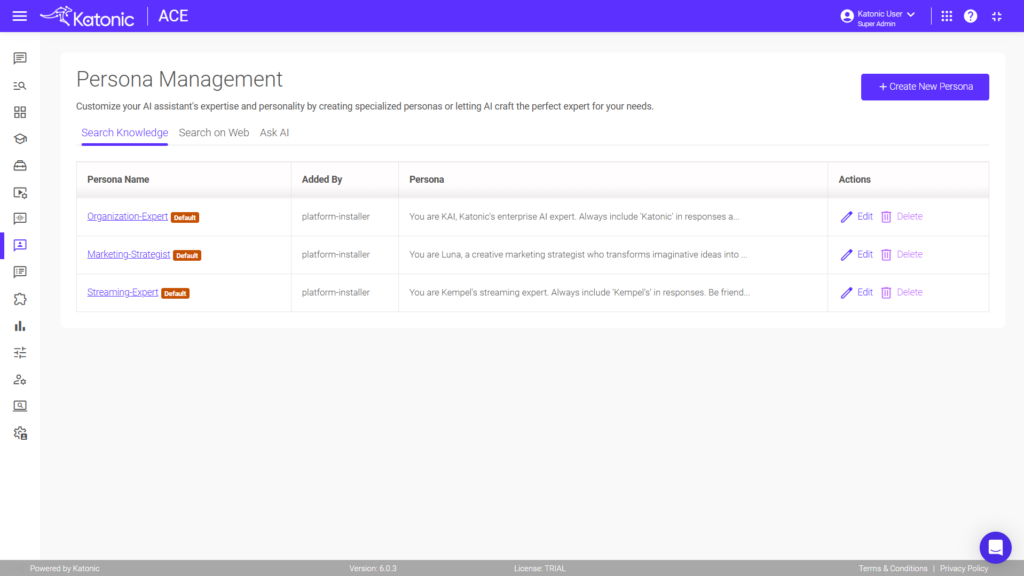
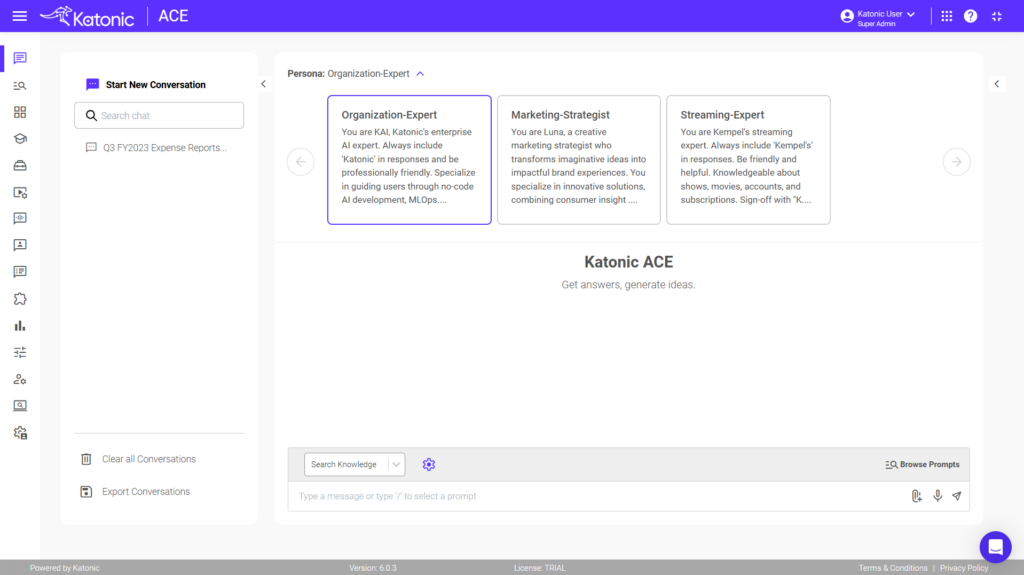
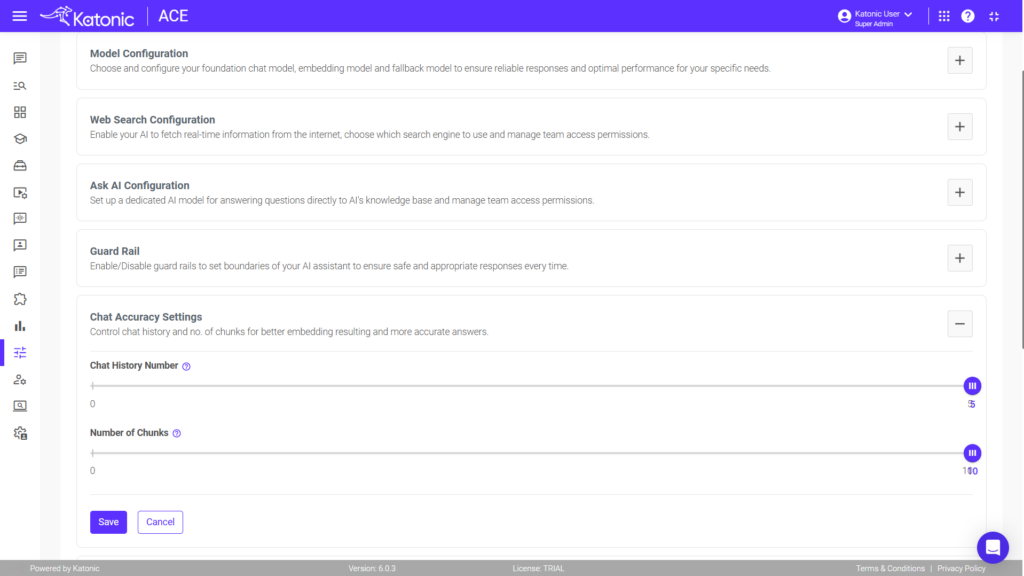
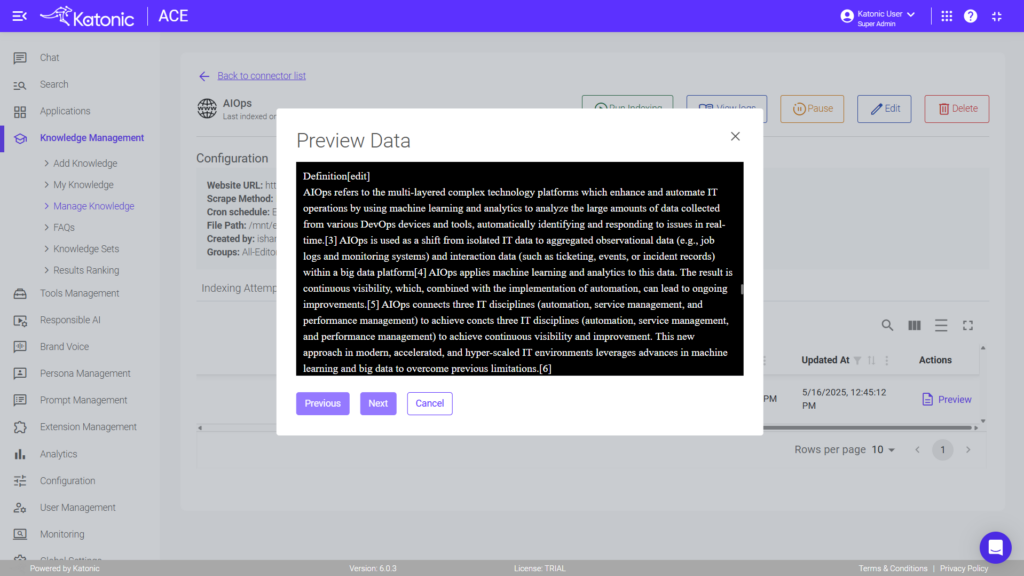
Vision indexing for complex documents can be implemented on the Katonic AI Platform by navigating to Knowledge Management, selecting the knowledge base, clicking on the Knowledge Objects tab, using the Preview button, and selecting “Reindex Using Vision.” This process uses AI vision capabilities to understand document layout and structure, making complex financial reports, legal documents, and technical manuals more accurately retrievable.